- Documentation
- Key Concepts
- Release Notes
Calling the IMDb API — TypeScript, Java & Python Examples
We've put together some examples on how to call the API using the AWS CLI, TypeScript, Java and Python, check them out to get started.
- Calling via AWS CLI / Postman / GraphQL Playground
- One-off query with Typescript / Java / Python
To begin calling the API you must have followed the instruction detailed on the Getting Access To The API page.
Calling via AWS CLI
Simplest way to test our API is calling through the AWS CLI.
Prerequisites:
- You must have the AWS CLI installed on your computer.
Example Command 1:
Retrieving the IMDb rating and the count of votes for the Titanic (1997) by supplying a very simple query in the body parameter. Simply replace the data-set-id, revision-id, asset-id and api-key with your own id's.
aws dataexchange send-api-asset \
--data-set-id <Put your Dataset ID here> \
--revision-id <Put your Revision ID here> \
--asset-id <Put your Asset ID here> \
--request-headers "{ \"x-api-key\": \"your-api-key-here\"}" \
--region us-east-1 \
--body "{ \"query\": \
\"{ title(id: \\\"tt0120338\\\") { \
ratingsSummary { \
aggregateRating \
voteCount } \
} }\" \
}"
Example Command 2:
Retrieving the title, the IMDb rating, the count of votes and the first 10 cast of the Matrix (1999) by supplying a slightly more complex query in the body parameter.
aws dataexchange send-api-asset \
--data-set-id <Put your Dataset ID here> \
--revision-id <Put your Revision ID here> \
--asset-id <Put your Asset ID here> \
--request-headers "{ \"x-api-key\": \"your-api-key-here\"}" \
--region us-east-1 \
--body "{\"query\": \
\"{ \
title(id: \\\"tt0133093\\\") { \
titleText { \
text \
} \
ratingsSummary { \
aggregateRating \
voteCount \
} \
credits(first: 10, \
filter: \
{ categories: [\\\"actor\\\", \\\"actress\\\", \\\"self\\\"] }) { \
edges { \
node { \
... on Cast { \
name { \
nameText { \
text \
} \
} \
} \
} \
} \
} \
} \
}\"}"
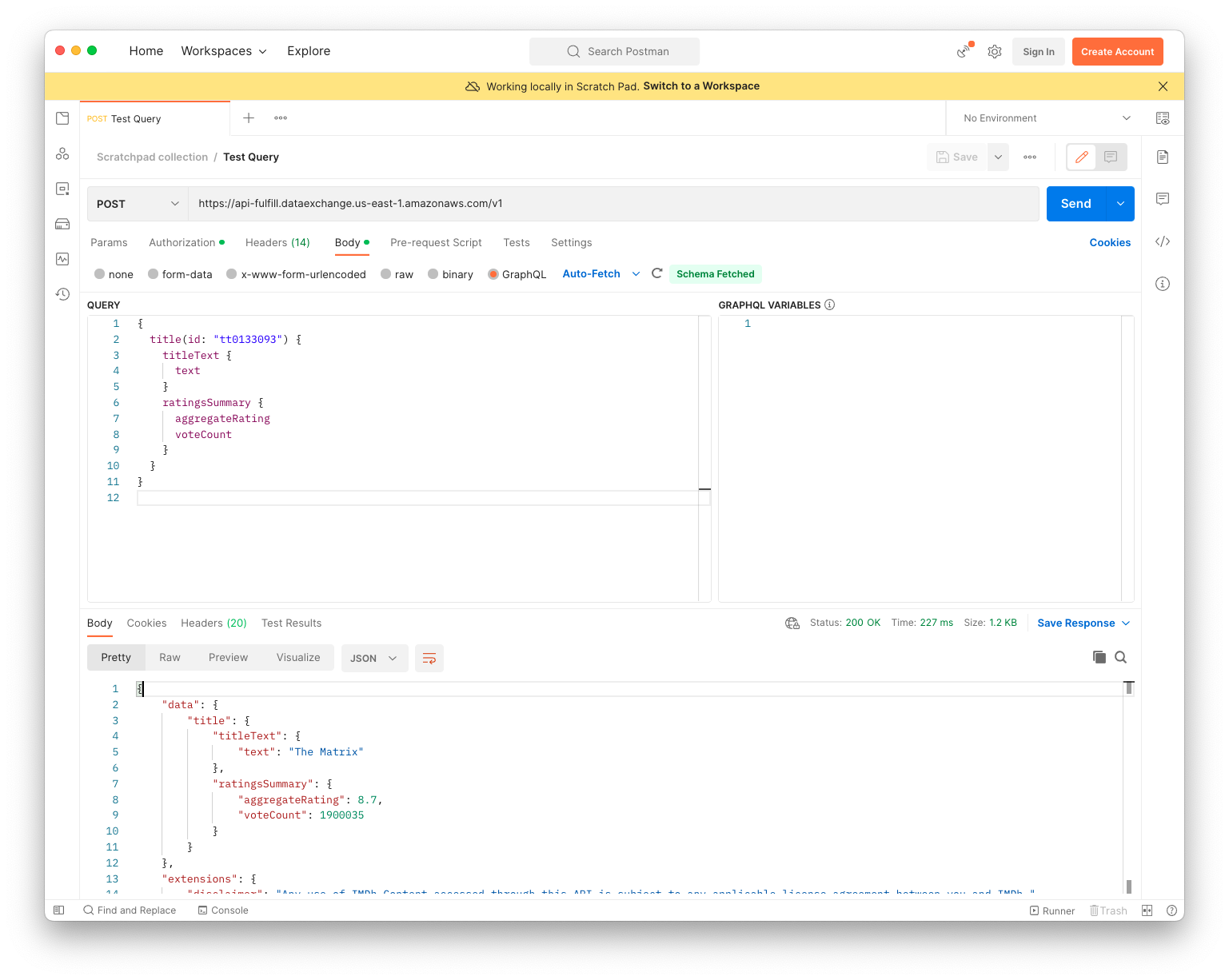
Calling via Postman
To be able to send requests to the IMDb real-time API via Postman you have to sign the requests with AWS Sigv4 signatures. The following guide will help you set the parameters in Postman correctly so you could use it to send queries to the API.
Prerequisites:
Have your AWS Access Key ID and AWS Secret Access Key ready.
Please be aware that saving your AWS Access Key ID and AWS Secret Access Key in Postman is considered a security risk and you should fully protect your Postman workspace/collection/request from unauthorized access to avoid the disclosure of your AWS credentials.
Have the following information ready. You will need these:
- AWS Data Exchange Data set ID
- AWS Data Exchange Revision ID
- AWS Data Exchange Asset ID
- IMDb API Key
Create a new request in Postman
- Set the Method to POST
- The request URL should be https://api-fulfill.dataexchange.us-east-1.amazonaws.com/v1
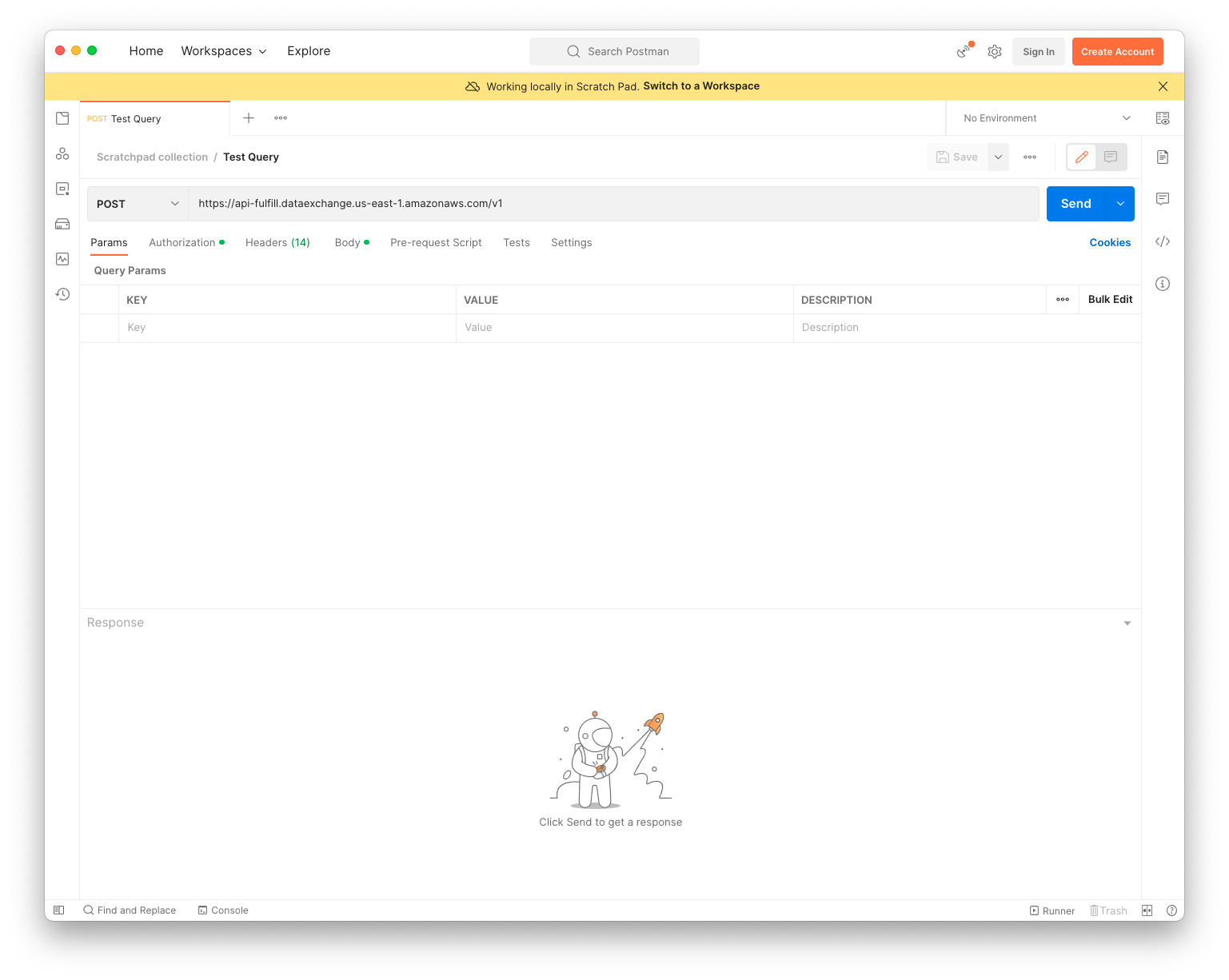
Authorization
- Select Authorization tab
- Set Type to be AWS Signature
- Set Add authorization data to to be Request Headers
- Set AccessKey to your AWS Access Key ID
- Set SecretKey to your AWS Secret Access Key
- Set AWS Region to us-east-1
- Set Service Name to dataexchange
- Leave Session Token empty
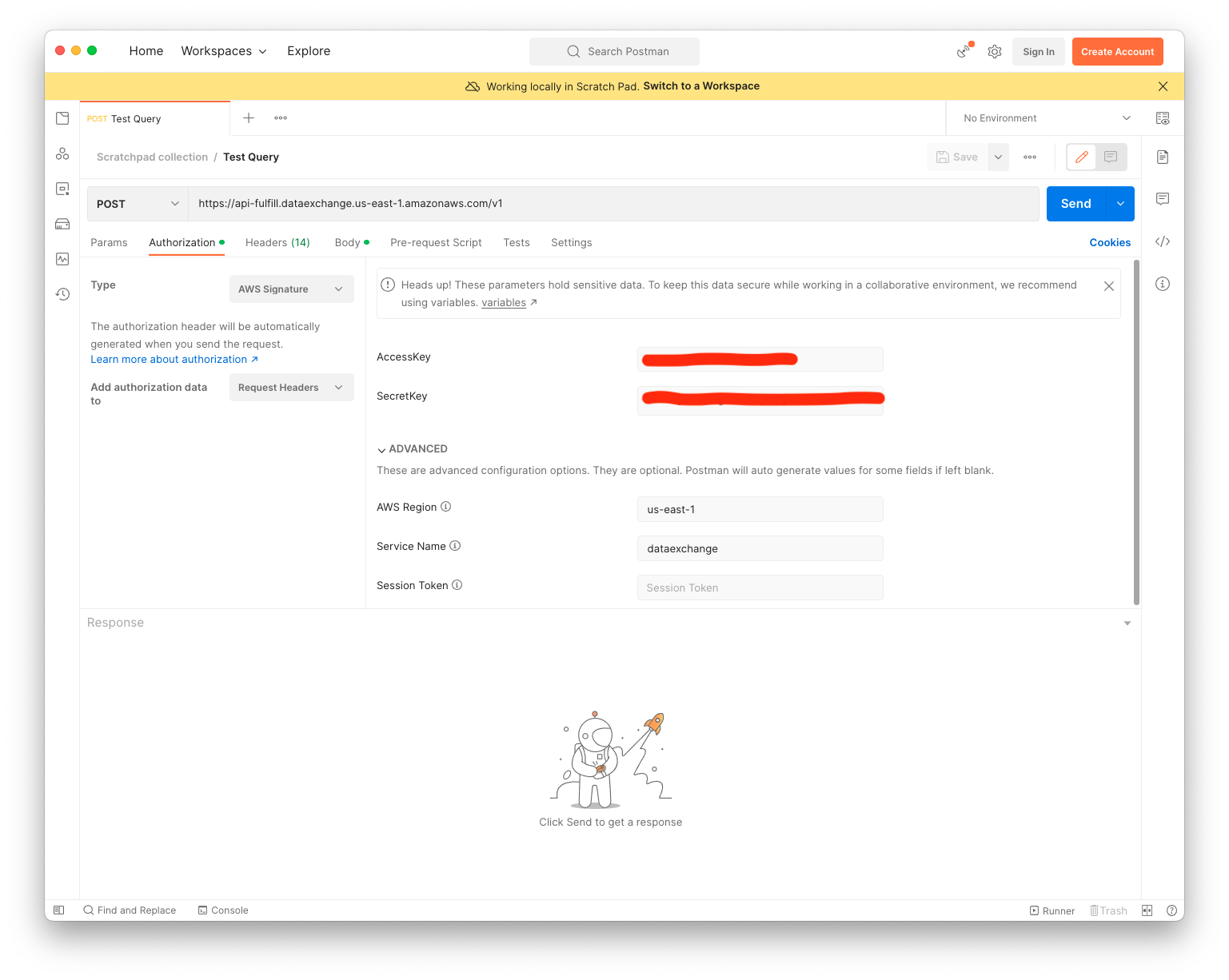
Query
- Select Body tab
- Select GraphQL
- And paste this into the text editor:
{
title(id: "tt0133093") {
titleText {
text
}
ratingsSummary {
aggregateRating
voteCount
}
}
}
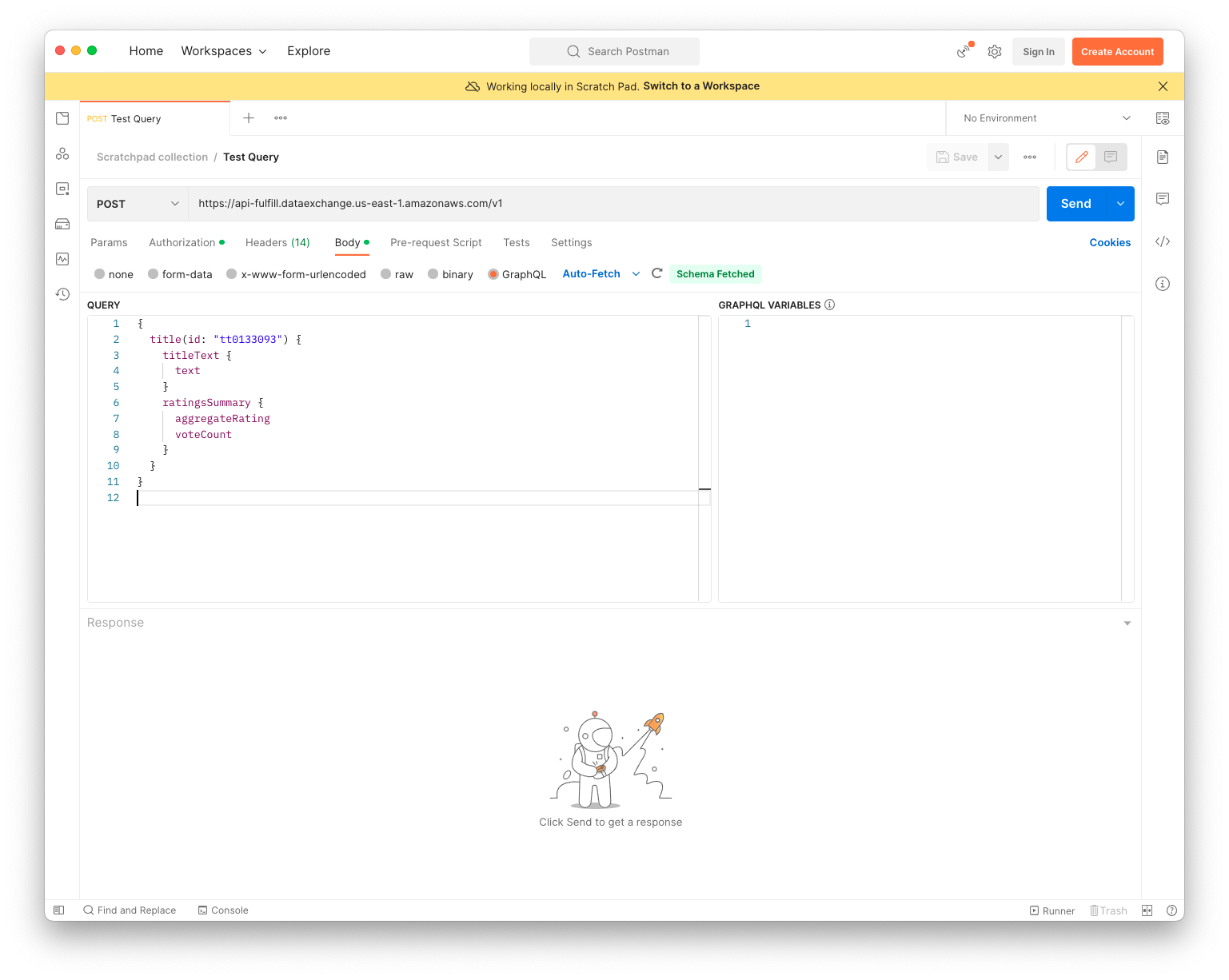
Headers
- Select Headers tab
- Make sure Content-Type is set to application/json
- Add a new key x-amzn-dataexchange-data-set-id with a value of your Data set ID
- Add a new key x-amzn-dataexchange-revision-id with a value of Revision ID
- Add a new key x-amzn-dataexchange-asset-id with a value of Asset ID
- Add a new key x-api-key with a value of your IMDb API key
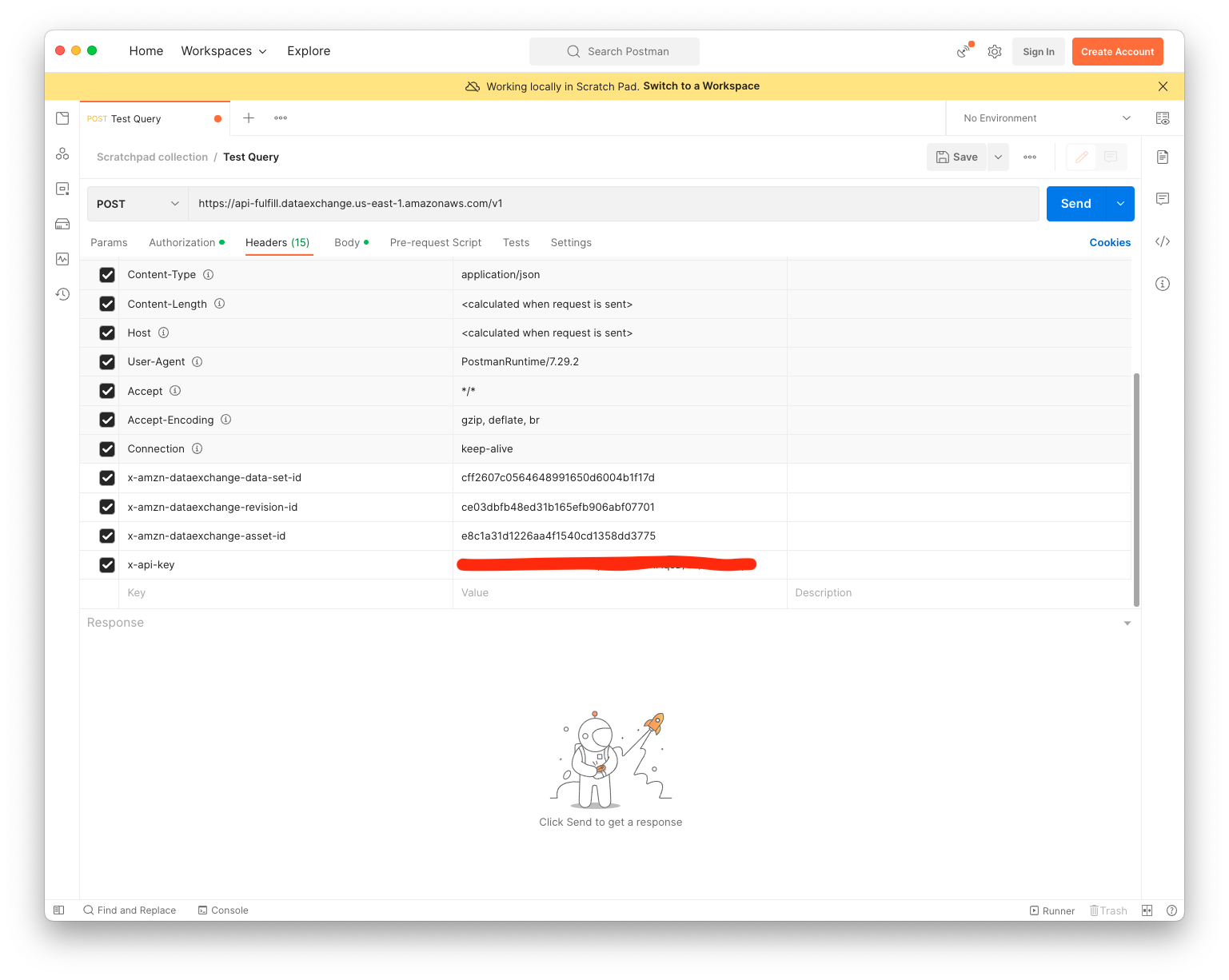
Now you can press Send and you should see a response similar to the below.
{
"data": {
"title": {
"titleText": {
"text": "The Matrix"
},
"ratingsSummary": {
"aggregateRating": 8.7,
"voteCount": 1900035
}
}
},
"extensions": {
"disclaimer": "Any use of IMDb Content accessed through this API is subject to any applicable license agreement between you and IMDb."
}
}
GraphQL Playground example using TypeScript
The GraphQL Playground is a graphical, interactive, in-browser GraphQL IDE. It offers syntax highlighting and query autocompletion based on the IMDb API schema helping you construct and test complex queries.
The following guide illustrates how to create a simple local proxy server which proxies requests from your browser to AWS data exchange. This local proxy server allows you to run the GraphQL playground.
1. Create a project with the following command:
$ npm init -y
2. Install required packages by running the following commands:
npm install --save @aws-sdk/client-dataexchange
npm install --save http
npm install --save-dev @types/node
npm install --save-dev ts-node
npm install --save-dev typescript
3. Create a file called imdb_playground_proxy_script.ts and add the following typescript content. Replace the asset-id, revision-id, data-set-id, and the apiKey with the values associated with your subscription (these are the values you saved in the Locate IDs and API Key section).
import {
DataExchangeClient,
SendApiAssetCommand,
} from "@aws-sdk/client-dataexchange";
import { createServer } from "http";
// Replace these 4 values with your own values
const assetId = "<Put your Asset ID here>";
const datasetId = "<Put your Dataset ID here>";
const revisionId = "<Put your Revision ID here>";
const apiKey = "<Put your API Key here>";
const port = 8080;
(async () => {
console.log(
`AWS Data Exchange dataset ID: ${datasetId}\nAWS Data Exchange revision ID: ${revisionId}\nAWS Data Exchange asset ID: ${assetId}\n\nForwarding requests to AWS Data Exchange...\nPlayground started at: http://localhost:${port}/playground\n`
);
const dataExchangeClient = new DataExchangeClient({ region: "us-east-1" });
const server = createServer(
async (createServerIncomingMessage, serverResponse) => {
let createServerData = "";
createServerIncomingMessage.on("connection", function () {});
createServerIncomingMessage.on("data", function (chunk) {
createServerData += chunk;
});
createServerIncomingMessage.on("end", async function () {
const body = createServerData;
const method = createServerIncomingMessage.method!;
try {
const command = new SendApiAssetCommand({
AssetId: assetId,
Body: body,
DataSetId: datasetId,
Method: method,
Path: createServerIncomingMessage.url!,
RevisionId: revisionId,
RequestHeaders: {
"x-api-key": apiKey,
"Content-Type": "application/json",
},
});
const response = await dataExchangeClient.send(command);
serverResponse.writeHead(200, response.ResponseHeaders!);
serverResponse.end(response.Body!);
} catch (error: any) {
serverResponse.writeHead(error.statusCode ?? 400);
serverResponse.end(
error.message ?? JSON.stringify({ message: "UnknownError" })
);
}
});
createServerIncomingMessage.on("error", (error) => {
serverResponse.end(error.message);
});
}
);
server.listen(port);
})();
4. Ensure you are Authenticated with AWS following the instructions in the AWS Authentication Section.
5. Execute the script and evaluate the response
Execute the script by running:
$ npx ts-node imdb_playground_proxy_script.ts
The console should print out something similar to:
AWS Data Exchange dataset ID: 32e95e857a5a2bd2302f739170202b0e
AWS Data Exchange revision ID: 94e2e1374633793d3a48dbe18cb48a15
AWS Data Exchange asset ID: 659636f24abc9e5fcd132af685fa10a8
Forwarding requests to AWS Data Exchange...
Playground started at: http://localhost:8080/playground
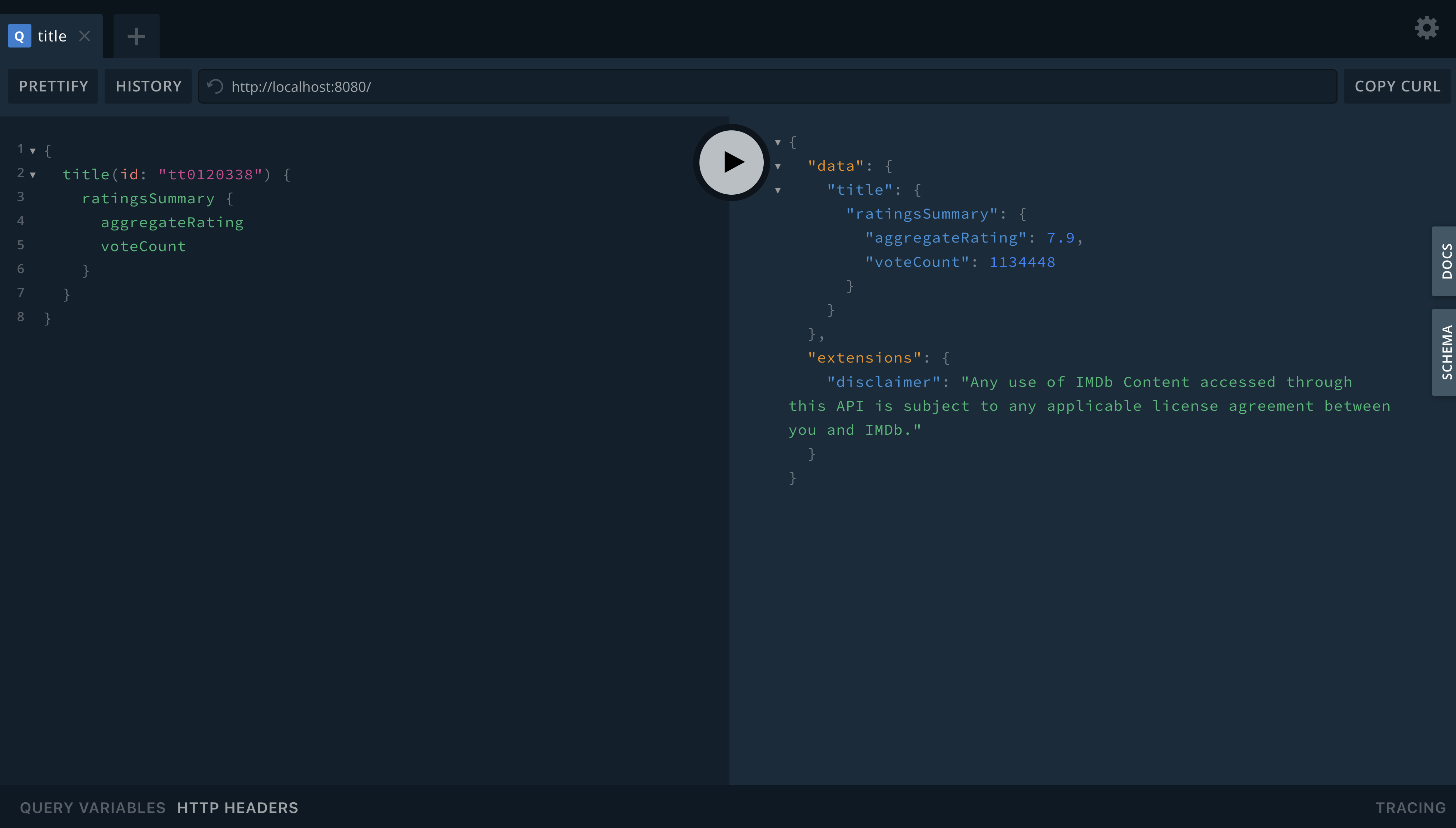
Open http://localhost:8080/playground in your browser, this should present a site that looks like this:
![]()
6. Run and evaluate a query
Copy the following query into the query box on the left, then press play to execute the query.
{
title(id: "tt0120338") {
ratingsSummary {
aggregateRating
voteCount
}
}
}
Running this query should return a json response on the right response box like this:
{
"data": {
"title": {
"ratingsSummary": {
"aggregateRating": 7.9,
"voteCount": 1133828
}
}
},
"extensions": {
"disclaimer": "Any use of IMDb Content accessed through this API is subject to any applicable license agreement between you and IMDb."
}
}
7. Craft your own queries
Go wild with the playground and get answers to all your burning entertainment questions powered by the IMDb API.
One-off API query example using TypeScript
For this example, we will use a GraphQL query to request ratings data on Titanic (1997).
{
title(id: "tt0120338") {
ratingsSummary {
aggregateRating
voteCount
}
}
}
The id value in the query comes from the identifier IMDb uses for this title.
The following steps will guide you through making a GraphQL call to the IMDb API:
1. Create a project with the following command.
$ npm init -y
2. Install required packages by running the following commands.
npm install --save @aws-sdk/client-dataexchange
npm install --save-dev @types/node
npm install --save-dev ts-node
npm install --save-dev typescript
3. Create a file called titanicRatingsQuery.graphql with the following content
{
title(id: "tt0120338") {
ratingsSummary {
aggregateRating
voteCount
}
}
}
4. Create a file called imdb_api_request.ts and add the following typescript content. Replace the asset-id, revision-id, data-set-id, and the apiKey with the values associated with your subscription (these are the values you saved in the Locate IDs and API Key section).
import {
DataExchangeClient,
SendApiAssetCommand,
} from "@aws-sdk/client-dataexchange";
import { readFileSync } from "fs";
// Replace these 4 values with your own values
const assetId = "<Put your Asset ID here>";
const datasetId = "<Put your Dataset ID here>";
const revisionId = "<Put your Revision ID here>";
const apiKey = "<Put your API Key here>";
const path = "/v1";
const method = "POST";
// Query we saved earlier
const titanicRatingsQuery = readFileSync(
"./titanicRatingsQuery.graphql",
"utf-8"
);
const body = JSON.stringify({ query: titanicRatingsQuery });
const dataExchangeClient = new DataExchangeClient({ region: "us-east-1" });
(async () => {
try {
const command = new SendApiAssetCommand({
AssetId: assetId,
Body: body,
DataSetId: datasetId,
RequestHeaders: {
"x-api-key": apiKey,
"Content-Type": "application/json",
},
Method: method,
Path: path,
RevisionId: revisionId,
});
const response = await dataExchangeClient.send(command);
console.log(JSON.stringify(JSON.parse(response.Body!), null, 4));
} catch (error: any) {
console.error(`Request failed with error: ${error}`);
}
})();
5. Ensure you are Authenticated with AWS following the instructions in AWS Authentication
6. Execute the script and evaluate the response
Execute the script by running:
$ npx ts-node imdb_api_request.ts
Executing this script should return a JSON response like this in the console.
{
"data": {
"title": {
"ratingsSummary": {
"aggregateRating": 7.9,
"voteCount": 1133828
}
}
},
"extensions": {
"disclaimer": "Any use of IMDb Content accessed through this API is subject to any applicable license agreement between you and IMDb."
}
}
The response to our query “what is the rating for titanic” is 7.9 stars out of 10.
One-off API query example using Java
Prerequisites:
- You must have the Java Development kit 8+ installed
- You must have Apache Maven installed
1. Create a Maven project.
Run the Following command to create a Maven project
mvn archetype:generate -DgroupId=org.AccessingImdbApiExample -DartifactId=imdb-api -DarchetypeArtifactId=maven-archetype-quickstart -DarchetypeVersion=1.4 -DinteractiveMode=false
2. Add this BOM to pom.xml, with the latest available version.
<dependencyManagement>
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>bom</artifactId>
<version>2.16.60</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
3. Specify the individual modules from the AWS SDK in pom.xml.
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>auth</artifactId>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>apache-client</artifactId>
</dependency>
</dependencies>
4. Add the following maven-compiler-plugin configuration in pom.xml.
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>dependency/</classpathPrefix>
<mainClass>org.AccessingImdbApiExample.App</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
You should now have pom.xml that looks something like this:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example.AccessingImdbApiExample</groupId>
<artifactId>myapp</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>AccessingImdbApiExample</name>
<url>http://maven.apache.org</url>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>bom</artifactId>
<version>2.16.60</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>auth</artifactId>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>apache-client</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>dependency/</classpathPrefix>
<mainClass>org.AccessingImdbApiExample.App</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
</project>
5. Replace the contents of src/main/java/org/AccessingImdbApiExample/App.java with the following:
package org.AccessingImdbApiExample;
import java.io.BufferedReader;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URI;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.HashMap;
import java.util.Map;
import java.util.stream.Collectors;
import com.fasterxml.jackson.databind.ObjectMapper;
import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider;
import software.amazon.awssdk.auth.signer.Aws4Signer;
import software.amazon.awssdk.auth.signer.params.Aws4SignerParams;
import software.amazon.awssdk.core.sync.RequestBody;
import software.amazon.awssdk.http.HttpExecuteRequest;
import software.amazon.awssdk.http.HttpExecuteResponse;
import software.amazon.awssdk.http.SdkHttpClient;
import software.amazon.awssdk.http.SdkHttpFullRequest;
import software.amazon.awssdk.http.SdkHttpMethod;
import software.amazon.awssdk.http.apache.ApacheHttpClient;
import software.amazon.awssdk.regions.Region;
public class App {
private static final String ENDPOINT = "https://api-fulfill.dataexchange.us-east-1.amazonaws.com/v1";
private static final String SERVICE_NAME = "dataexchange";
private static final String GRAPHQL_QUERY_PATH = "src/titanicRatingsQuery.graphql";
/*
* Replace ASSET_ID, REVISION_ID, DATA_SET_ID and API_KEY values with your own
* values
* Visit the following link for information on how to get your API keys and IDs:
* https://developer.imdb.com/documentation/api-documentation/getting-access/?ref_=java_one_off_q#locate-ids-and-api-key
*/
private static final String ASSET_ID = "<Your Asset ID>";
private static final String REVISION_ID = "<Your Revision ID>";
private static final String DATA_SET_ID = "<Your Data Set ID>";
private static final String API_KEY = "<Your API Key>";
public static void main(String[] args) throws IOException {
// Query that we are going to send to the API
String graphqlQuery = new String(Files.readAllBytes(
Paths.get(GRAPHQL_QUERY_PATH)), StandardCharsets.UTF_8);
Map<String, Object> graphqlRequestBodyObject = new HashMap<String, Object>();
graphqlRequestBodyObject.put("query", graphqlQuery);
String graphqlRequestBody = new ObjectMapper().writeValueAsString(graphqlRequestBodyObject);
// Construct a request.
SdkHttpFullRequest request = SdkHttpFullRequest.builder()
.uri(URI.create(ENDPOINT))
.method(SdkHttpMethod.POST)
.appendHeader("Content-Type", "application/json")
.appendHeader("x-amzn-dataexchange-asset-id", ASSET_ID)
.appendHeader("x-amzn-dataexchange-revision-id", REVISION_ID)
.appendHeader("x-amzn-dataexchange-data-set-id", DATA_SET_ID)
.appendHeader("x-api-key", API_KEY)
.contentStreamProvider(RequestBody.fromString(graphqlRequestBody).contentStreamProvider())
.build();
// Create an AWSv4 signer
Aws4Signer signer = Aws4Signer.create();
// Sign the request
request = signer.sign(request,
Aws4SignerParams.builder()
.awsCredentials(DefaultCredentialsProvider.create().resolveCredentials())
.signingRegion(Region.US_EAST_1)
.signingName(SERVICE_NAME)
.build());
// Make the request
SdkHttpClient httpClient = ApacheHttpClient.create();
HttpExecuteRequest.Builder requestBuilder = HttpExecuteRequest.builder().request(request);
request.contentStreamProvider().ifPresent(c -> requestBuilder.contentStreamProvider(c));
HttpExecuteResponse httpResponse = httpClient.prepareRequest(requestBuilder.build()).call();
// Print the response
InputStream responseBodyInputStream = new ByteArrayInputStream(
httpResponse.responseBody().get().readAllBytes());
String responseBodyContent = new BufferedReader(
new InputStreamReader(responseBodyInputStream))
.lines().collect(Collectors.joining("\n"));
System.out.println("Response Body: " + responseBodyContent);
}
}
6. Replace the values for ASSET_ID, REVISION_ID, DATA_SET_ID and API_KEY in src/main/java/org/AccessingImdbApiExample/App.java with your own values.
7. Create a new file called titanicRatingsQuery.graphql in the src directory with the following content:
{
title(id: "tt0120338") {
ratingsSummary {
aggregateRating
voteCount
}
}
}
8. Ensure you are Authenticated with AWS following the instructions in AWS Authentication
9. Run the following commands to compile the code into bytecode and run the resulting jar.
mvn install clean
mvn package
mvn dependency:copy-dependencies
java -jar target/imdb-api-1.0-SNAPSHOT.jar
10. Evaluate the response
Executing this code should return a JSON response like this in the console.
{
"data": {
"title": {
"ratingsSummary": {
"aggregateRating": 7.9,
"voteCount": 1138920
}
}
},
"extensions": {
"disclaimer": "Any use of IMDb Content accessed through this API is subject to any applicable license agreement between you and IMDb."
}
}
One-off API query example using Python
For this example, we will use a GraphQL query to request ratings data on Titanic (1997).
{
title(id: "tt0120338") {
ratingsSummary {
aggregateRating
voteCount
}
}
}
The id value in the query comes from the identifier IMDb uses for this title.
The following steps will guide you through making a GraphQL call to the IMDb API:
1. Install boto3 by running the following command:
pip install boto3
2. Create a file called titanicRatingsQuery.graphql with the following content
{
title(id: "tt0120338") {
ratingsSummary {
aggregateRating
voteCount
}
}
}
3. In the same directory that you created the GraphQL query in the previous step, create a file called imdb_api_request.py and add the following python content. Replace the asset-id, revision-id, data-set-id, and the apiKey with the values associated with your subscription (these are the values you saved in the Locate IDs and API Key section).
import json
import boto3
# Instantiate DataExchange client
CLIENT = boto3.client('dataexchange', region_name='us-east-1')
# Replace these 4 values with your own values
DATA_SET_ID = '<Put your Dataset ID here>'
REVISION_ID = '<Put your Revision ID here>'
ASSET_ID = '<Put your Asset ID here>'
API_KEY = '<Put your API Key here>'
# Query we saved earlier
query_file = open("titanicRatingsQuery.graphql", "r")
query = query_file.read()
query_file.close()
BODY = json.dumps({'query': query})
METHOD = 'POST'
PATH = '/v1'
response = CLIENT.send_api_asset(
DataSetId=DATA_SET_ID,
RevisionId=REVISION_ID,
AssetId=ASSET_ID,
Method=METHOD,
Path=PATH,
Body=BODY,
RequestHeaders={
'x-api-key': API_KEY
},
)
# This will print the IMDb API GraphQL Response
print(f"Response Body: {response['Body']}")
4. Ensure you are Authenticated with AWS following the instructions in AWS Authentication
5. Execute the script and evaluate the response
Execute the script by running:
$ python imdb_api_request.py
Executing this script should return a JSON response like this in the console.
{
"data": {
"title": {
"ratingsSummary": {
"aggregateRating": 7.9,
"voteCount": 1253887
}
}
},
"extensions": {
"disclaimer": "Any use of IMDb Content accessed through this API is subject to any applicable license agreement between you and IMDb."
}
}
The response to our query “what is the rating for titanic” is 7.9 stars out of 10.
Ready-to-run GraphQL query examples for titles, ratings, cast and crew, box office data, and search.